고수준 개념
이 문서는 자동 번역되었으며 오류가 포함될 수 있습니다. 변경 사항을 제안하려면 Pull Request를 열어 주저하지 마십시오.
LlamaIndex.TS는 사용자 정의 데이터를 사용하여 LLM 기반 애플리케이션 (예: Q&A, 챗봇)을 구축하는 데 도움이 됩니다.
이 고수준 개념 가이드에서는 다음을 배울 수 있습니다:
- LLM이 사용자의 데이터를 사용하여 질문에 답하는 방법.
- 질의 파이프라인을 구성하기 위한 LlamaIndex.TS의 주요 개념 및 모듈.
데이터 전체에서 질문에 답하기
LlamaIndex는 데이터와 함께 LLM을 사용할 때 두 단계 방법을 사용합니다:
- 인덱싱 단계: 지식 베이스를 준비하고
- 질의 단계: 질문에 대답하기 위해 LLM에게 관련 컨텍스트를 검색하여 전달
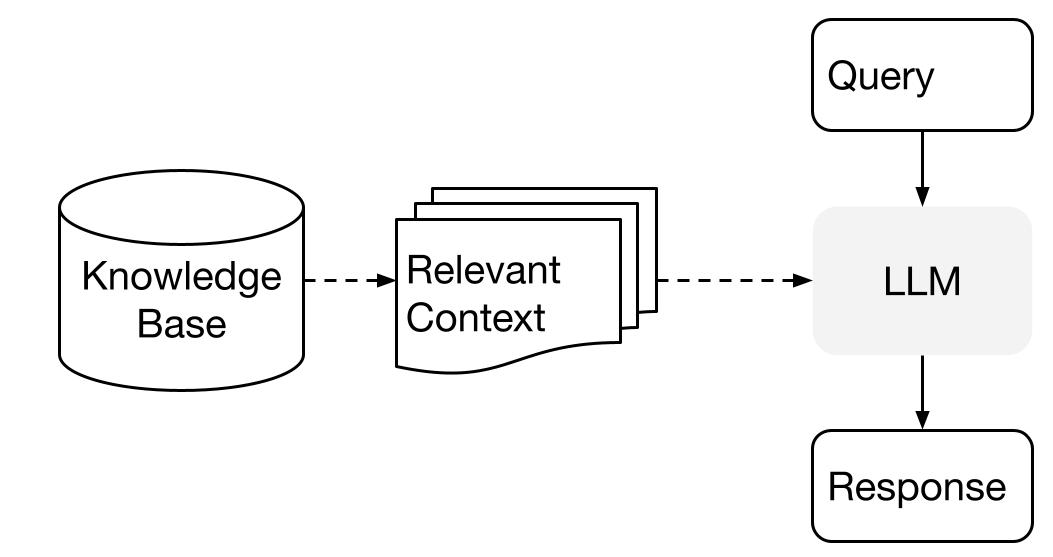
이 프로세스는 검색 증강 생성 (RAG)로도 알려져 있습니다.
LlamaIndex.TS는 이러한 단계를 모두 쉽게 수행할 수 있는 필수 도구를 제공합니다.
자세한 내용을 살펴보겠습니다.
인덱싱 단계
LlamaIndex.TS는 데이터 커넥터와 인덱스의 모음을 사용하여 지식 베이스를 준비하는 데 도움이 됩니다.

데이터 로더:
데이터 커넥터 (즉, Reader)는 다양한 데이터 소스와 데이터 형식에서 데이터를 간단한 Document 표현 (텍스트 및 간단한 메타데이터)으로 가져옵니다.
문서 / 노드: Document는 모든 데이터 소스 (예: PDF, API 출력 또는 데이터베이스에서 검색한 데이터)를 감싸는 일반적인 컨테이너입니다. Node는 LlamaIndex에서 데이터의 원자 단위이며 소스 Document의 "덩어리"를 나타냅니다. 이것은 메타데이터와 관계 (다른 노드와의 관계)를 포함하여 정확하고 표현력있는 검색 작업을 가능하게 하는 풍부한 표현입니다.
데이터 인덱스: 데이터를 가져온 후에는 LlamaIndex가 검색하기 쉬운 형식으로 데이터를 인덱싱하는 데 도움이 됩니다.
LlamaIndex는 내부적으로 원시 문서를 중간 표현으로 파싱하고 벡터 임베딩을 계산하며 데이터를 메모리에 저장하거나 디스크에 저장합니다.
"
질의 단계
질의 단계에서 질의 파이프라인은 사용자 질의에 가장 관련성 높은 컨텍스트를 검색하고, 그것을 LLM에게 전달하여 응답을 합성합니다.
이를 통해 LLM은 원래의 훈련 데이터에 없는 최신 지식을 얻을 수 있으며, (환각을 줄이는) 환경을 제공합니다.
질의 단계에서의 주요 도전은 (잠재적으로 많은) 지식 베이스에 대한 검색, 조율 및 추론입니다.
LlamaIndex는 Q&A (질의 엔진), 챗봇 (채팅 엔진) 또는 에이전트의 일부로 사용하기 위해 RAG 파이프라인을 구축하고 통합하는 데 도움이 되는 조립 가능한 모듈을 제공합니다.
이러한 구성 요소는 순위 지정 기본 설정을 반영하고 구조화된 방식으로 여러 지식 베이스에 대한 추론을 수행하기 위해 사용자 정의할 수 있습니다.
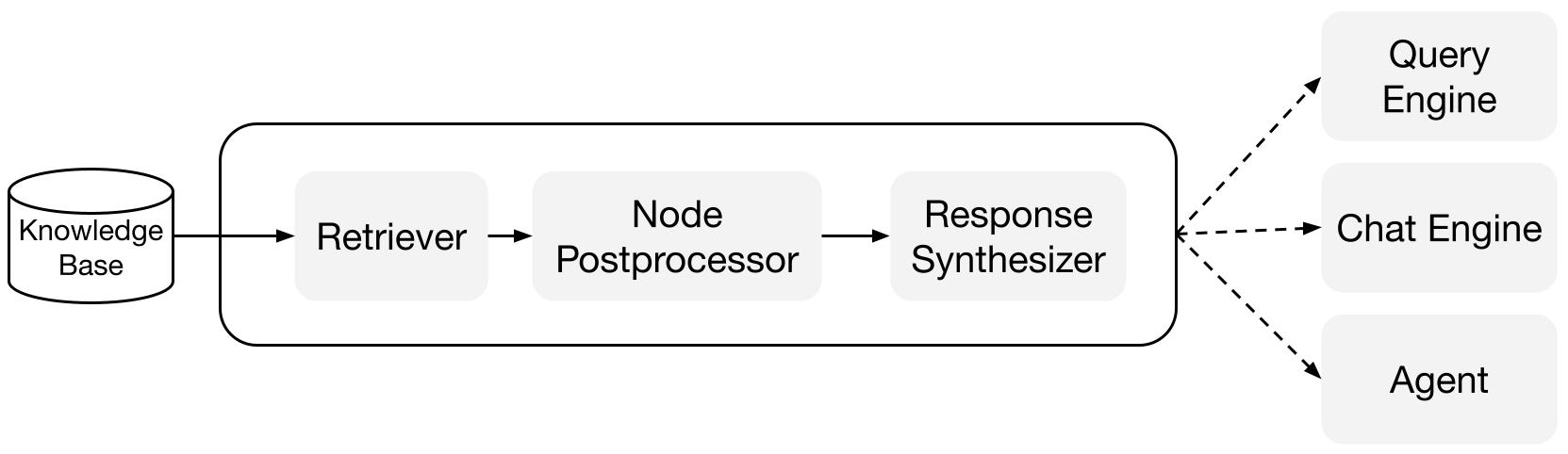
구성 요소
검색기: 검색기는 쿼리가 주어졌을 때 지식 베이스 (즉, 인덱스)에서 관련 컨텍스트를 효율적으로 검색하는 방법을 정의합니다. 구체적인 검색 로직은 다양한 인덱스에 따라 다르며, 가장 인기 있는 것은 벡터 인덱스에 대한 밀집 검색입니다.
응답 합성기: 응답 합성기는 LLM에서 사용자 쿼리와 검색된 텍스트 청크 세트를 사용하여 응답을 생성합니다.
"
파이프라인
질의 엔진: 질의 엔진은 데이터에 대해 질문을 할 수 있는 종단 간 파이프라인입니다. 자연어 질의를 입력으로 받아 응답과 함께 LLM에게 전달되는 참조 컨텍스트를 반환합니다.
채팅 엔진: 채팅 엔진은 단일 질문 및 답변이 아닌 데이터와의 다중 질문 및 대화를 위한 종단 간 파이프라인입니다.
"